
Python网络爬虫 _XPath解析【6】
问题引入:
前面我们可以通过HTTP Requests请求获取到网站的HTML源代码,但是仍没有得到我们想要的信息。 那怎么办呢,这时我们就需要通过代码解析,从复杂的源码中提取出我们想要的信息。
爬虫解析器
爬虫解析器用作于从复杂的网页代码中解析提取出我们想要的数据。如下图,通过解析我们可以从结构复杂的代码中提取出我们想要的。
爬虫解析器有三大类,分别是正则表达式解析器,Bs解析器和Lxml解析器。
其对于的解析方法如下:- 正则表达式解析:正则表达式(Regular Expression) 简称 ‘Re’ 是一种特殊的字符串模式,利用这些元字符可以从结构复杂的文本中简化,提取出匹配的内容,是最传统的爬虫解析方式。
- BeautifulSoup解析:用于从HTML和XML文件中提取数据。它能够解析HTML文档,从中提取出标签、属性、文本等内容,方便我们进行二次开发和数据分析。
- XPath解析:当前最为流行的解析方式,通过标签定位解析提取出目标信息。
由于XPath相对其他解析方法具有解析精度高,速度快,和操作灵活的特点,所以我们才用XPath作为我们解析器去提取数据。
什么是XPath?
- XPath:XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
- XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式,另外它还提供了超过 100 个内建函数用于字符串、数值、时间的匹配以及节点、序列的处理等等,几乎所有我们想要定位的节点都可以用XPath来选择。
作用
- XPath的最初作用是搜索Xml代码中的目标,但后来也可以用作于HTML的代码搜索,它可以在复杂的代码中筛选提取出目标代码,以至于现在被称为‘无能标记语’。
- 在网络爬虫领域中,XPath扮演这重要的角色,爬虫在处理复杂的网页源码时,同样可以利用XPath来解析提取出你想要的数据。
XPath解析
- 前面说过,当我们拿到页面源码后,并不能直接得到我们想要的数据,这时我们则需要用到爬虫解析器XPath,任何使用呢?看操作:
1.安装Lxml库
XPath是第三方库,所以我们需要进行安装才可以使用。
安装只需要在终端输入一下命令即可:
如果安装失败,可以尝试切换安装源。默认安装
pip install lxml
清华大学镜像源(推荐)
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
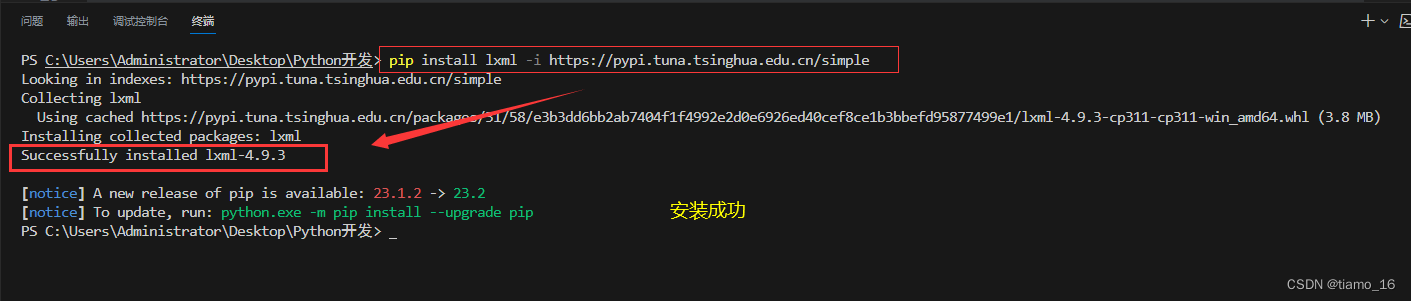
若显示” Successfully installed lxml “则说明安装成功了。
!
若显示” Requirement already satisfied “则说明已经安装过了,无需再安装。

3. 完事之后就可以正常使用XPath了。
2.提取数据
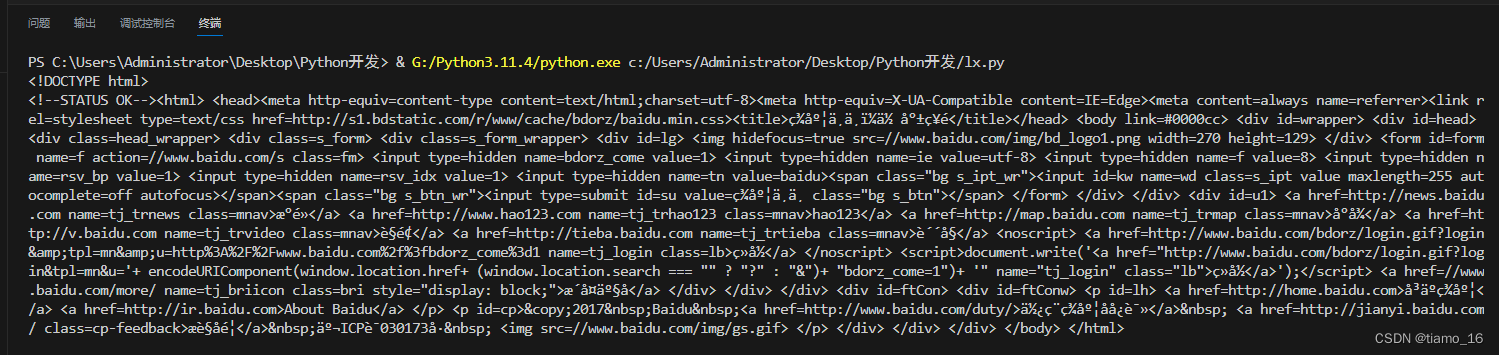
- 我们先看一下百度的原页面,再看一下运行代码后的效果。可以看到代码杂乱无章,很难让人想到这两张图有任何关联,但其实页面显示的一切都被包含在HTML代码内。只是经过浏览器的渲染,才得到页面内的效果。
- 现在我们开始真正的使用XPath解析来从代页面代码中提取出我们想要的内容。
假如我们只想要得到百度热搜内的数据,要怎么样提取呢?
- 首先新建一个Py文档,导入Requests库和安装好的lxml库。定义一个请求对象也就是百度,之后再定义一个请求头传给请求内的headers可选参数这是为了将程序伪装成浏览器,防止服务器拒绝接受请求,将请求到的页面代码储存到容器中,respones_text容器内的就是百度页面的HTML源代码了。
1 | import requests # 导入请求库 |
- 获取到源代码后,我们就可以定义一个要解析的对象了,引用的etree,因为我们解析的对象是HTML代码,使用用HTML()方法,括号参数是获取到的百度源码respones_text。
1 | import requests # 导入请求库 |
- 定义好解析对象后,就可以使用XPath更加精确的定位到我们想要的内容。在浏览器F2打开检查功能,使用圆圈内的定位小箭头指向你想提取的内容,比如百度热搜的第一条内容,右侧就会显示该内容的HTML源码位置。
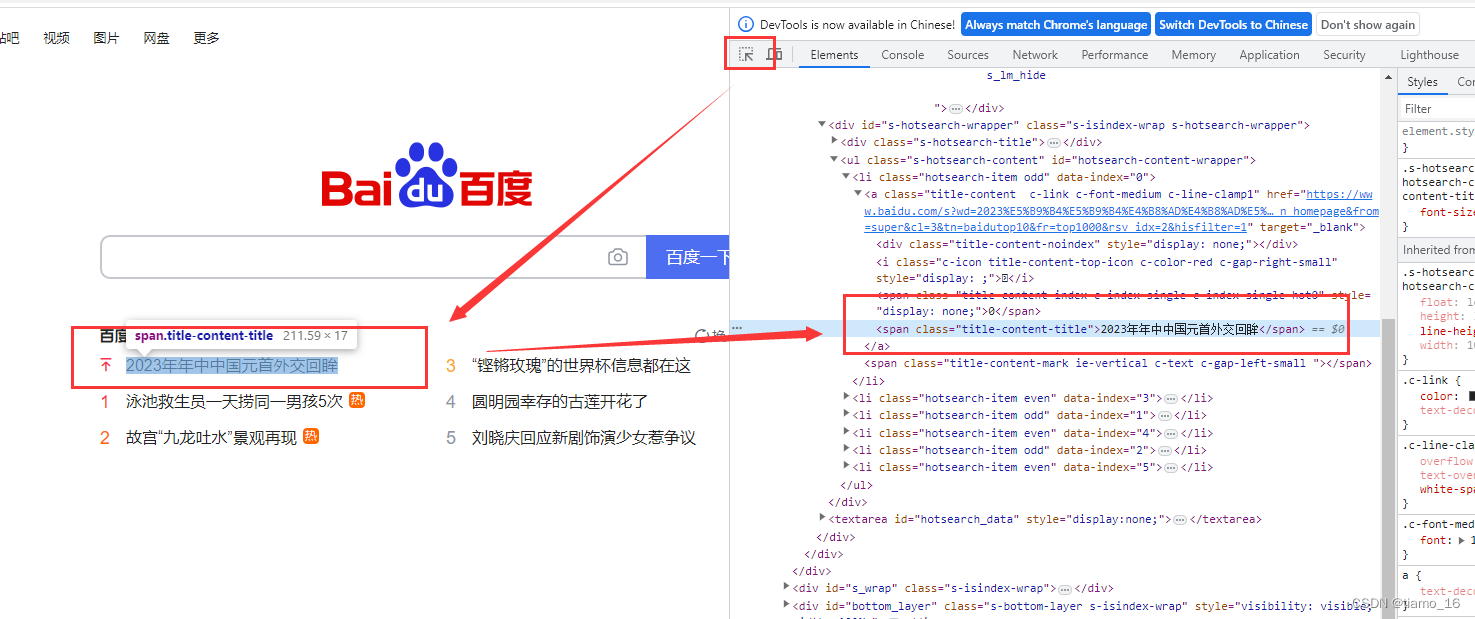
- 找到了源码位置后,我们就可以通过分析这串标签代码来完成提取。可以看到内容被包含在Span标签内,我们右键该标签Copy—> Copy XPath复杂该标签的XPath层级位置。
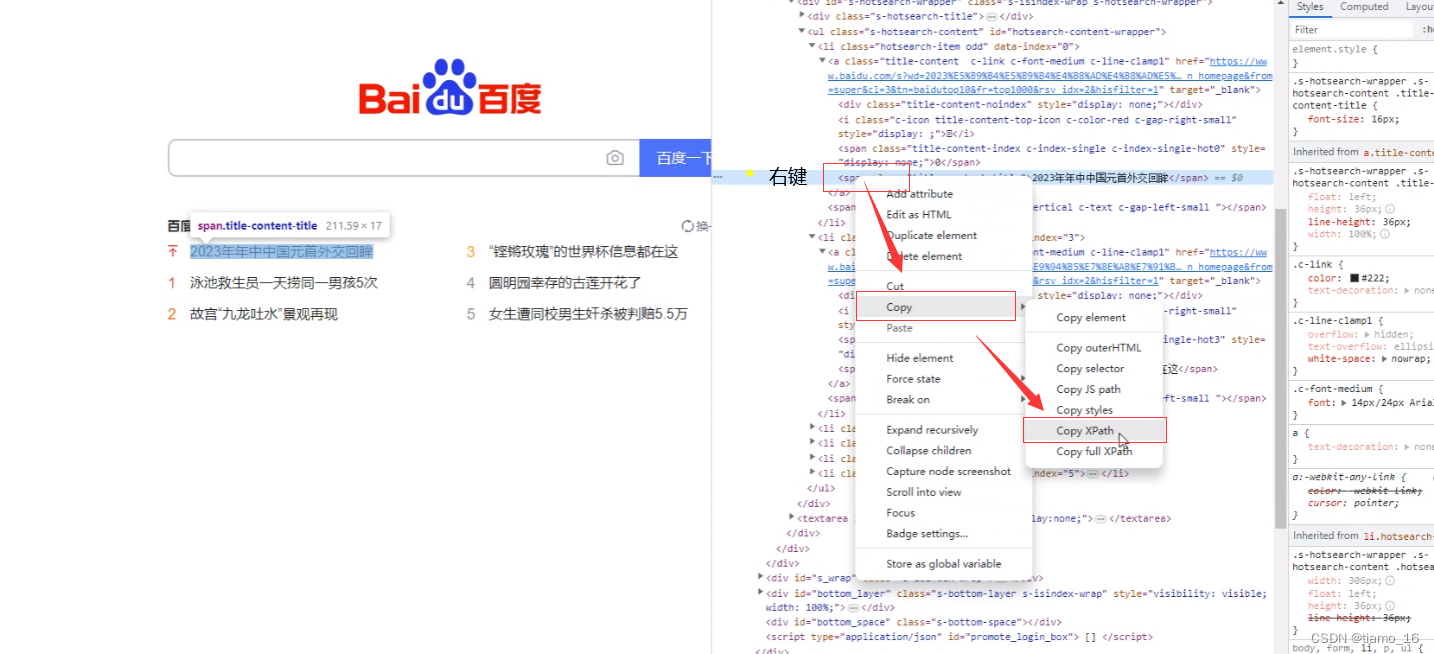
7. 定义一个容器对象,利用xpath()方法将复制下来的标签路径内的数据提取出来,并保存到容器内。xpath()内的参数就是复制下来的路径。
1 | import requests # 导入请求库 |
- 我们运行这串代码,可以看到只是输出span元素的信息,仍没有我们需要的。

::::: :别急,我们只需要在路径后面加上个/text()即可
1 | after = objects.xpath('//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]/text()') # 获取层级标签内的数据 |
运行一下,成功地将我们想要的内容解析提取了出来!!!
- 那有人要问了,如果我想将热搜中所有的词条全搞出来,怎么弄呢?
很简单,通过分析源码我们可以发现,包含内容的span标签的都有一个共同的属性值:class=’’title-content-title’’,利用这一发现我们XPath快速定位。
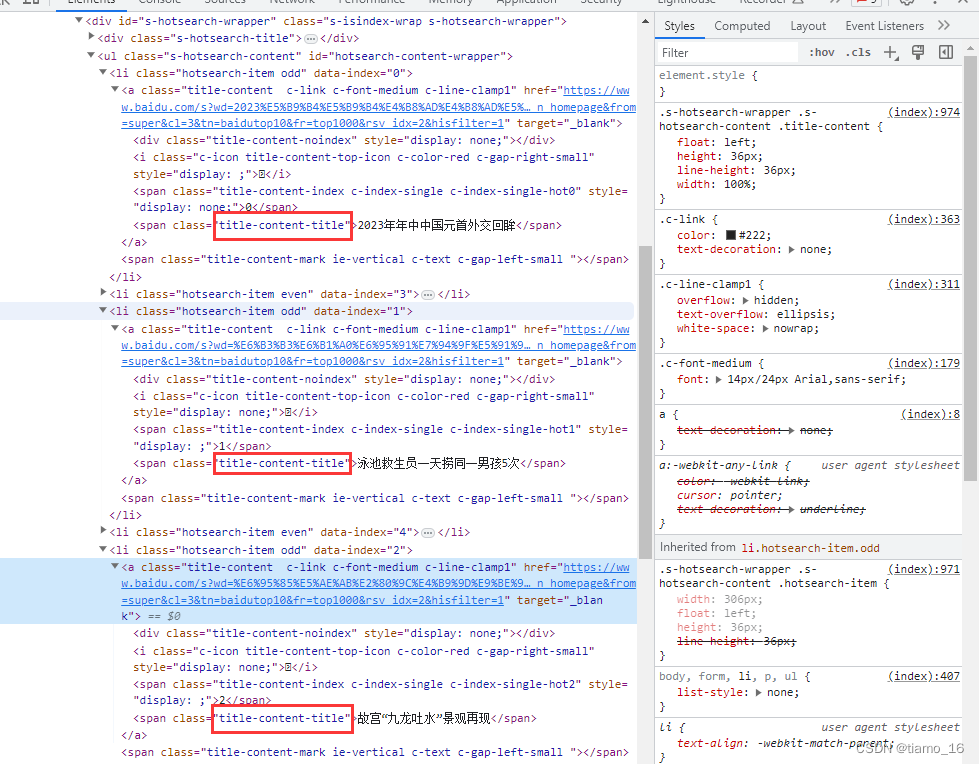
10. 我们可以利用XPath指定标签属性,以快速的定位到目标内容。
这样我们再次运行,就可以得到所有热搜词条了。
1 | after = objects.xpath('//span[@class="title-content-title"]/text()') # 获取层级标签内的数据 |

- 因为XPath提取到到数据一般都是以列表的形式储存的,所以我们可以用循环语句将数据迭代给新的容器以达到自动换行美化数据的效果。
1 | import requests # 导入请求库 |
- 怎么样?整个过程下来是不是简单又神奇,这也正是XPath功能强大的所在。
总结
- 本次简单地讲到了XPath用作于提取内容的过程。
- 作为当前最流行火爆的爬虫解析器,其根本因素它拥有强大的数据分析能力和多样的定位功能,让爬虫有了更多的选择。
- 以上只是XPath的简单操作,其精髓还需要更加深入的探索和学习。
- 内容为本人学习笔记,难免有不足之处,恳请大家批评指正。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Almango!
相关推荐

2023-07-16
Python网络爬虫 _反爬虫【4】
1.由于网络爬虫具有一定的弊端,使用网络爬虫可以悄无声息的从互联网上获取很多资源,包括一些付费,原创和不公开的资源。所以很多大型网站都采取了反爬虫机制,来抵御爬虫的不正当行为。 2.本次介绍了什么是反网络爬虫?,简单的爬虫伪装操作?以及如何应对网络爬虫?。 什么是反网络爬虫? 反爬虫:**是指对扫描器中的网络爬虫环节进行反制,它会根据ip访问频率,浏览网页速度和User-Agent等参数来判断是否为网络爬虫,随后通过一些反网络爬虫机制来阻止或妨碍网络爬虫的正常爬取。**以此达到网络爬虫恶意获取网站资源的效果。 爬虫伪装1. 什么是爬虫伪装? 爬虫伪装:指的是将爬虫伪装成其他工具, 我们知道请求头中的User-Agent是用于告诉服务器请求是通过什么工具发出的(浏览器,程序,),以及工具对应的版本和类型是什么。 现在大多网站,都会根据User-Agent的参数来判断请求是否为网络爬虫发出的,服务器都希望访问网站的用户,是浏览器发出的请求,而不是爬虫程序。因为爬虫本身就是一种程序,所以就会被反爬虫机制给阻止。 我们只需要将User-Agent的参数更改一下即可。 2....
2023-07-13
Python网络爬虫_发送HTTP请求【3】
了解HTTP协议相关知识后,我们可以尝试利用Python发送一次HTTP请求。Request是Python的第三方库,用于构建和发送HTTP请求。 安装Requests: 因为是第三方库,所以我们需要用到命令行终端的pip来进行安装。 打开终端,输入 pip install requests 再回车。 当显示如图所示,则表示安装成功了。 #安装成功: 但是如果显示如下,则表示你已经安装过了Requests,不需要再进行安装了。 #安装失败(重复): 打开该库后可以看到里面包含了很多方法模块,而我们待会就会用到里面的status_codes 编写代码:1. 发送HTTP请求 当Requests库安装好之后,就到了编写Python代码的环节了,新建一个py文本。 导入Requests模块。因为爬虫的主要行为是爬取内容,所以我用GET请求方法,获取一个服务器对象。我们拿百度为例。get内写的是要获取的完整的URL。 注意:URL要带上http协议,加密协议带https。 123import requests # 导入模块send =...
2023-07-26
Python网络爬虫 _简易的翻译小程序【7】
1.了解了URL封装和XPath解析后,也掌握了许多爬虫知识,是时候做个实战演练了。2.本期内容会讲到如何利用爬虫制作一个简易的翻译小程序。 制作翻译小程序一. 实战对象 先声明一下:本次实战案例是以学习为目的,不会有其他恶意行为,文章仅供参考。 这次是利用爬虫制作小程序,那当然离不开网站了,本次我们会以,金山词霸为实战素材。 二. 制作流程1. 英文翻译 首先我们先打开金山词霸的官网页面。 我们直接翻译两个单词,注意一下URL地址的变化,可以发现,,w=后面的就是我们要翻译的中文,连续两次翻译都是只是改变了这一小部分,所以,我们就可以利用到这一发现。 3....
2023-07-11
Python网络爬虫_HTTP请求与响应【2】
问题引入: 网络爬虫爬取的对象的是Web,我们将它称之为服务端,而爬虫就是本地的客户端。那么要怎样才能使客户端与服务端建立连接并爬取数据呢?这时就需要利用HTTP了 什么是HTTP?1.HTTP:超文本传输协议(Hypertext Transfer Protocol,简称:HTTP)它是一个简单的请求-响应协议,架构运行在TCP之上。这套协议定义了客户端可发送什么样的请求(Request)信号和服务器可返回什么样的响应(Response)。它的作用是规定www服务器与浏览器之间信息传递规范,是二者共同遵守的协议。 2.当用户使用浏览器输入网址访问目标网站时,需要向网站服务器发送HTTP请求,通过发送请求即可从服务器获取页面内容的响应。但实际上服务器只会发送网页代码,我们所看到的页面效果是经过浏览器渲染而成的。 请求类型:1.HTTP请求类型有八种:(GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT)2.但我们常用的只有两种**:GET**和POST。 GET : 用于获取数据,一般用于搜索排序和筛选之类的操作。 POST...
2023-07-14
Python网络爬虫_URL封装【5】
为了达到便于管理的目的,大多网站会对网页的URL地址采取封装措施。 URL封装 在我们访问网站时,通常会看到不一样的网址,就如豆瓣电影的动作片排行榜的网页路径一样。并不是一个很层级形式的路径。 这就是URL封装。 3. 可以发现,URL路径中,从里面的问号开始往后就是封装的内容。 4. 像URL路径这样的,一般以Json的形式存在于请求的Request Payload,内参数用于指定路径。准确来说应该是一种请求体。5. 我们打开检查查看Payload6. 可以发现,Payload参数完全对应着URL的后半部分。 如果我们把这个Payload放入代码中拼接起来会咋样呢因为像这样的参数我们需要将它们写成字典再传入Params可选参数,即可。 123456789101112131415import requests # 导入请求库tou = { # 伪装浏览器 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...
2023-07-11
Python网络爬虫_初识【1】
本次教程是依据个人学习心得与学习记录所做,见证的是我们的成长。 什么是网络爬虫?定义: Web...
评论