C++数组及其基本特征的浅层解读【4】
- 在Python或者是C#接触数组的时候可没那么多要注意的点,到了C++,好家伙,全是知识点。
- 这里我也懒得写太多原理性的东西,直接记一下基本常识和怎么去用就行。
声明数组
1 . 声明一个数组其实就是告诉编译器申请一个数组变量。
2 . 和C#一样,它的声明格式为:Type VarName[];,不难理解,在变量名后面加个[]中括号,就表示它是个数组。
3 . 例如我要声明一个整数数值:
1 | int IntArray[]; |
4 . 当然,也可以声明各种数据类型的数组
1 | int VarName1[]; // 声明一个整数数组 |
4 . 但要注意的是 当数组的类型为int,那么它的元素只能是整数类型的数据,是什么类型的数值,就是什么类型的数据。
初始化数组
1 . 声明一个数组后,当我们需要使用它的时候就需要对其进行初始化,也就是你要对这个数组做什么,编译器就会给该数组分配合适的内存。
2 . 初始化数值就相当于是你给该数组第一次设定的最原始的值,或者仅指定最原始的大小。
3 . 下面是两种不同的初始化方法。
方法一
- 该方法仅对数值的大小进行初始化,并未对其掺入元素。
- 在中括号内指定为5,意思就是将其初始化为含5个整数元素的数组。这个时候编译器会为数组分配足够的内存来存储5个整型元素。
1 | int IntArray[5]; |
方法二(常用)
- 该方法直接对其数值进行参入最原始的值
- 这个时候,编译器会根据数组元素的多少,对其进行内存分配,并确定数组的大小。
- 要注意的是,如果你事先指定了数组的大小,那么数值内的元素必须在该数值的大小范围内。
1 | int IntArray[] = {1, 3, 6, 3, 2}; |
修改数元素
1 . 效果数组内的元素,只需要通过下标索引获取需要修改的元素位置即可修改。
2 . 下标索引指定是元素的顺序序号,从最左边开始,第一个元素的索引值就是0,第二个元素的索引值就是1,,以此类推。
3 . 所以当我们需要修改某个元素的时候,我们可以这样操作:
1 | int IntArray[] = {1, 3, 6, 3, 2}; |
4 . 这个时候,原来的6就会被修改为43,最终数组的内容就是1, 3, 43, 3, 2。
数组在内存中的连续性解读
在C++中,数组的内存分配是连续的。这意味着数组的每个元素都存储在相邻的内存地址中,从数组的第一个元素开始,依次向后扩展。
1 . 下面会绘制了一张图,从图中可以将竖着的长条理解为一个数组,数组的每个元素都彼此紧贴并被包含在长条内,这样可以更加生动的理解数组在内存中的连续性。
2 . 数组在内存中的连续性具有多方面的优点,由于内存的连续性,数组元素的访问速度很快,因为CPU可以预读取内存,并且缓存行可以被有效利用。由于数组内存的连续性,你可以使用 memcpy 等函数来高效地复制整个数组。此外,当数组离开作用域或被销毁时,所有元素的内存将被释放,因为它们是连续存储的,这大大节省了内存的开销。而在元素访问上它也将变得更加方便。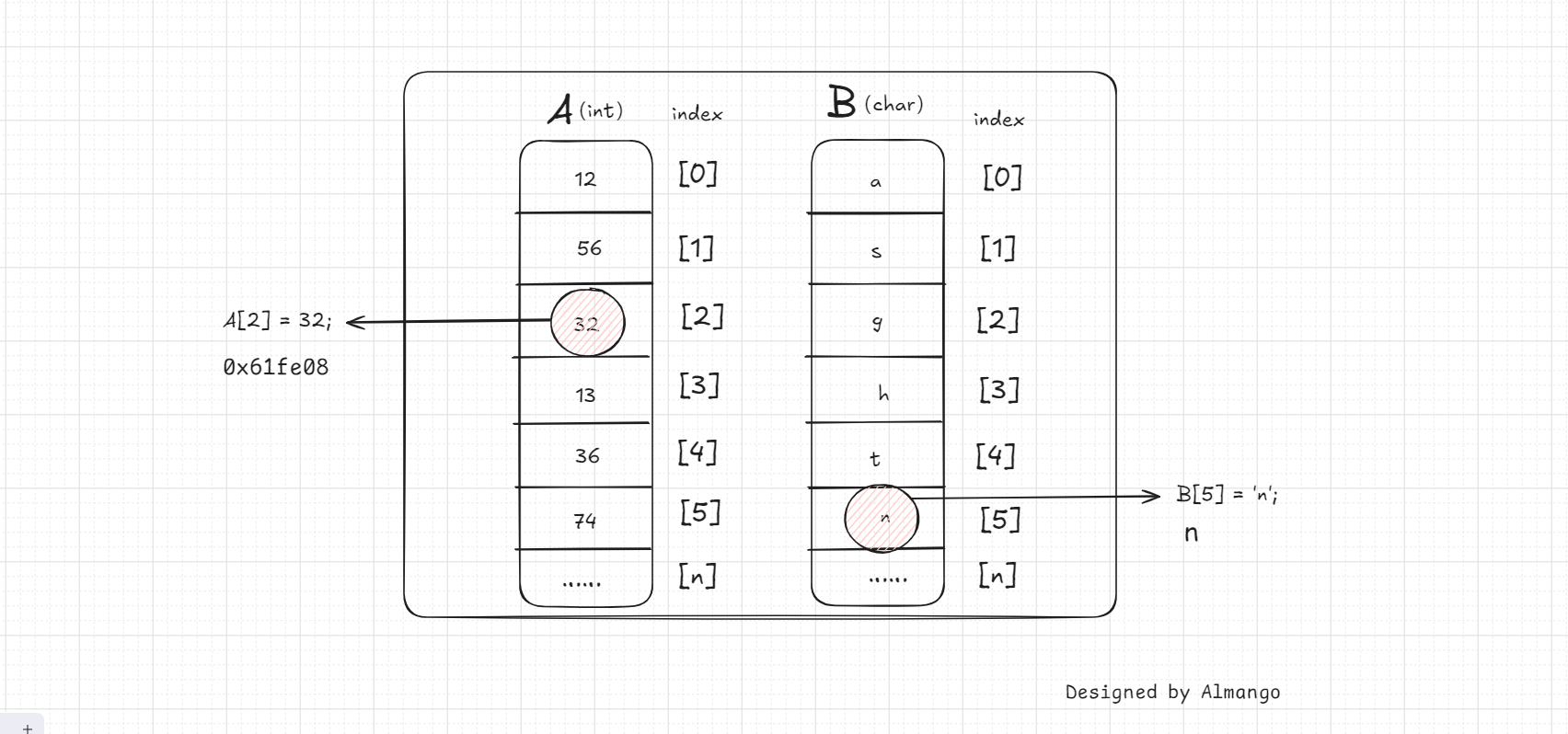
3 . 但这并不代表它十全十美。
由于数组元素是连续存储的,访问越界的元素可能会导致程序崩溃或不可预测的行为,因为可能会访问到不属于数组的内存区域。
4 . C++和其他编程语言在数组的特点上,有一点不太一样,就是:当你通过一个不存在的或者超出数组长度的索引来访问一个元素时,编译器并不会因此而报错,它会当做什么都没发生,最终你访问的元素它可能是无法预料的内存中的一个值(你不知道这个值来着哪里)。下面代码就是错误的示范。
1 | int IntArray[] = {12, 56, 32, 13, 36, 74}; |

5 . 可以看到通过使用一个超出数组范围的索引值,它输出了一个很奇怪的数字,它可能来源于内存的每个地方,当我们尝试修改这个值的时候,虽然它并没有报错,但如果大型项目犯这种错误,程序崩溃的可能性会更大。
6 . 基于这个不可预测的行为,若当你尝试修改了这个值,它可能会导致整个程序的崩溃。
基本数据类型在数值中的标准大小
1 . 我们知道,数值可以可以声明为多种不同数据类型数值,如:整数数组,字符串数组,布尔数值等等。但当我们将其初始化之后,不同数据类型数组内的元素的标准内存大小都不一样,所以编译也会根据数据类型来分配内存。
2 . 这里是不同数据类型的标准内存大小:
int:4字节char:1字节float:4字节double:8字节string:32字节
应用1:获取数组最后一个元素
根据不同数据类型内存大小的分配,我们可以通过
sizeof()方法来获取到元素的总个数,并求得最后一个元素。
1 . sizeof():该方法可以获取到数组的总大小,也就是编译器给它分配了多少内存。
2 . 结合下面代码,可以更直观的理解:
1 |
|

3 . 首先,我们知道,int类型的元素,其标准内存大小为4个字节,如果有6个元素,那么数组的总大小为24字节。
4 . 通过sizeof()函数我们可以拿到数组的总大小,我们将其除以4,得到的就是元素的总个数,由于数组的索引是从0开始排的,所以我们再减去1,得到的就是最后一个元素的下标索引了,以此得到其元素内容。
5 . 当然了,如果要拿到倒数第二个元素,就减去2,以此类推。
6 . 这就是基本数据类型在数值中的标准大小的一个基本应用。
应用2:遍历数组元素
1 . 通过拿到数组的总个数,我们可以给数组写一个for循环来遍历出它的所有元素。
2 . 看代码可以理解,就不再解释。
1 |
|