C#(CSharp)学习笔记_程序的基本结构【二】
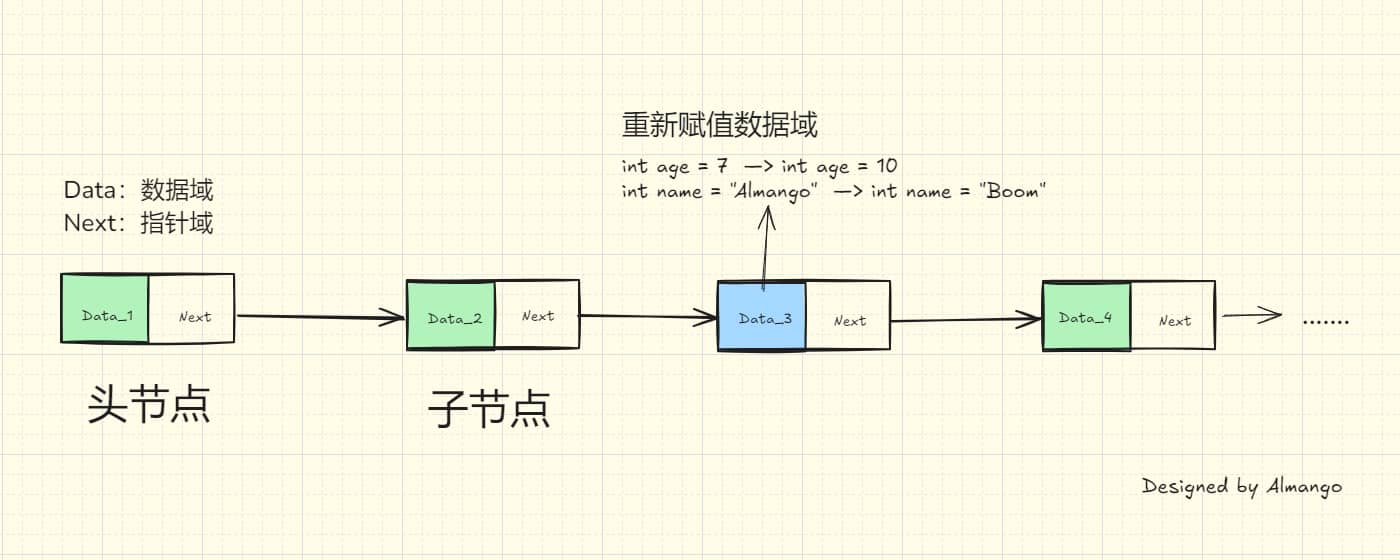
前言: 对于一个初学者来说,理解程序的基本结构是非常有必要的,我们可以知道代码的用途,用法和编写准则。 学习任何一门编程语言第一步都是输出“Hello World”,但途中我们会用到一些代码,而这些就是程序运行的最基本的结构。 看下面代码。是不是除了个“Hello World”,其他啥都不知道?那么接下来就让我们一起了解一下C#的那些基本程序结构吧!(注意:以下解释都是本人观点,一部分会拿Python做对比,就是说:通俗易懂吧……) 语法须知: C#的文件后缀为 .cs。 C#的语法和Java非常相似,对于大小写非常敏感,使用注意命名规则。 C#是以 花括号和 分号 来将代码分隔开来。 123456789101112using System; //引入System命名空间namespace helloWorld { class First_1 { static void Main(string[] args) { ...
C#(CSharp)学习笔记_前言及Visual Studio Code配置C#运行环境【一】
前言 这可以说是我第一次正式的踏入C#的学习道路,我真没想过我两年前是怎么跳过C#去学Unity3D游戏开发的(当然了,游戏开发肯定是没有成功的,都是照搬代码)。而现在,我真正地学习一下C#,就和去年学的Python那样。 C#对于我来说,可以做的和我想做的有很多,比如:桌面应用开发,移动应用开发,游戏开发,等等,不仅如此,学习C#对于我以后学习C/C++也是起到很大的帮助的。 虽然我对这门语言抱有很多看法,但是学总比不学好,谁叫我和它有如此缘遇。 希望我的路顺风顺水。 1.什么是C#和.NET?C# (C Sharp) C#是微软公司发布的一种由C和C++衍生出来的面向对象的编程语言、运行于.NET Framework和.NET...

Typora序列号破解【白嫖篇】
Typora编辑器 - 序列号破解 Typora 是一款由 Abner Lee 开发的轻量级 Markdown 编辑器,与其他 Markdown 编辑器不同的是,Typora...

2023我的创作纪念日
...

文章添加标签,封面,标题,日期(Hexo)
文章/导航页添加标签,封面,标题,日期(Hexo)我们只需要在写好的Markdown文本中的顶部加入这些代码即可12345678910111213`title: Python Socket TCP简单通信【二】 # 设置文章标题``date: 2017-05-27 13:47:33 # 设置发布时间(默认不设)``cover: img\post_ing\1.jpg # 设置文章封面(包括标题封面)``categories: # 添加分类``- Python``- 编程语言``- 网络编程` 1. 文章添加分类123categories: # 添加分类- Python- 编程语言 2. 文章添加标签123tags: # 添加标签- Python- 编程语言 1. 导航页添加封面123456---title: about date: 2024-01-01 22:46:09 ...
我的个人博客发布成功啦!!!
我的个人博客发布成功啦!!! 这大概是两年前的是吧?我曾一直希望自己能搭建并上传自己的个人博客,但是受服务器和虚拟机的影响(太贵了,时间久了,对于我们学生党来说,确实是不小的开支) 此外,还受到框架因素的影响,原本是采用原生的H5+CSS+JavaScript搭建博客的,后来有去WordPress,都不太行(这样的网站框架只能上传到虚拟机中)最后选择了Hexo框架:纯静态框架(因为GitHub和Gitee听说是可以免费托管静态网站的) 时长两年半,我最最终还是在Gitee中发布了。(真的花了我不少时间,尤其是在高三段) 网站框架采用:Hexo (Static...

FydeOS17国产操作系统全过程安装【保姆级教程】
@[toc] 系统介绍什么是FydeOS ? FydeOS (原名 Flint OS)是由燧炻科技创新(北京)有限责任公司基于开源项目 Chromium Project 二次开发,适配x86 与 ARM 硬件平台,定位于中国版的 Google Chrome OS。FydeOS提供包括操作系统产品定制化的技术咨询、解决方案以及商业授权服务。 FydeOS 是一款基于Linux+Chromium Project开发的轻量级操作系统,它的和Google的Chrome OS极为相似,有着ChromeBook和MacOS类似的使用体验,能够在大部分主流硬件上平稳运行,并且兼容Android应用程序和Linux。以浏览器平台为基础,加入更多符合国内用户习惯的本地化功能以提升用户体验。经过长期的技术积累,FydeOS 有能力运行在各种主流的硬件设备之中并提供围绕 FydeOS...

HarmonyOS4.0应用开发【学习笔记3:安装DevEco Studio开发环境】
DevEco Studio HUAWEI DevEco Studio 是基于IntelliJ IDEA...

Python网络爬虫 _简易的翻译小程序【7】
1.了解了URL封装和XPath解析后,也掌握了许多爬虫知识,是时候做个实战演练了。2.本期内容会讲到如何利用爬虫制作一个简易的翻译小程序。 制作翻译小程序一. 实战对象 先声明一下:本次实战案例是以学习为目的,不会有其他恶意行为,文章仅供参考。 这次是利用爬虫制作小程序,那当然离不开网站了,本次我们会以,金山词霸为实战素材。 二. 制作流程1. 英文翻译 首先我们先打开金山词霸的官网页面。 我们直接翻译两个单词,注意一下URL地址的变化,可以发现,,w=后面的就是我们要翻译的中文,连续两次翻译都是只是改变了这一小部分,所以,我们就可以利用到这一发现。 3....
Python网络爬虫 _XPath解析【6】
问题引入: 前面我们可以通过HTTP Requests请求获取到网站的HTML源代码,但是仍没有得到我们想要的信息。 那怎么办呢,这时我们就需要通过代码解析,从复杂的源码中提取出我们想要的信息。 爬虫解析器 爬虫解析器用作于从复杂的网页代码中解析提取出我们想要的数据。如下图,通过解析我们可以从结构复杂的代码中提取出我们想要的。 爬虫解析器有三大类,分别是正则表达式解析器,Bs解析器和Lxml解析器。其对于的解析方法如下: 正则表达式解析:正则表达式(Regular Expression) 简称 ‘Re’...